Information
This is my capstone project at Galvanize Data Science Immersrive - San Francisco (2016).
Introduction
Homograph words are words with the same spelling, but can have different meanings. The list of homograph words in English can be found in homograps.md. For example, as an old joke says:
Q: Why do you think movie stars are so cool?The twist here is that the words "cool" and "fans" have two different meanings. It is fairly simple for human to decide which meaning of a homograph word is used given the context where the word is in. But to train the computer to do the same is not a simple tasks. In Natural Language Processing, this challenge is call "word-sense disambiguation". Several algorithms have been developed, some are simple and some are very sophisticated. In this project, I attempted to explore the word sense disambiguation challenge with different type of models.
A: Because they have lots of fans.
The Data
The dataset I used for this project is obtainedfrom from the Senseval corpus where the meanings of the homographs are labeled in each example.
Methods and Results
Preprocessing of Data
For each homograph, the example sentences and their lables are split into two lists. The documents are then lemmatized and Tf-idf vectorized using scikit-learn libraries. Once the text documents are converted to numeric, For this project, there are two different approaches to classify the meanings of the homographs: semi-supervised and supervised learnings.
1. Semi-Supervised Learning
This approach ignores the labled meanings of the homgraphs in their examples and attempts to classify the meanings using clusterings. The reason behind this is that if there can be words that appear mulitple times, unsupervised cluserings may be able to detect some useful patterns that can help the classification process. Then the labels were used to determine the accuracy, precision and recall rates of the models.
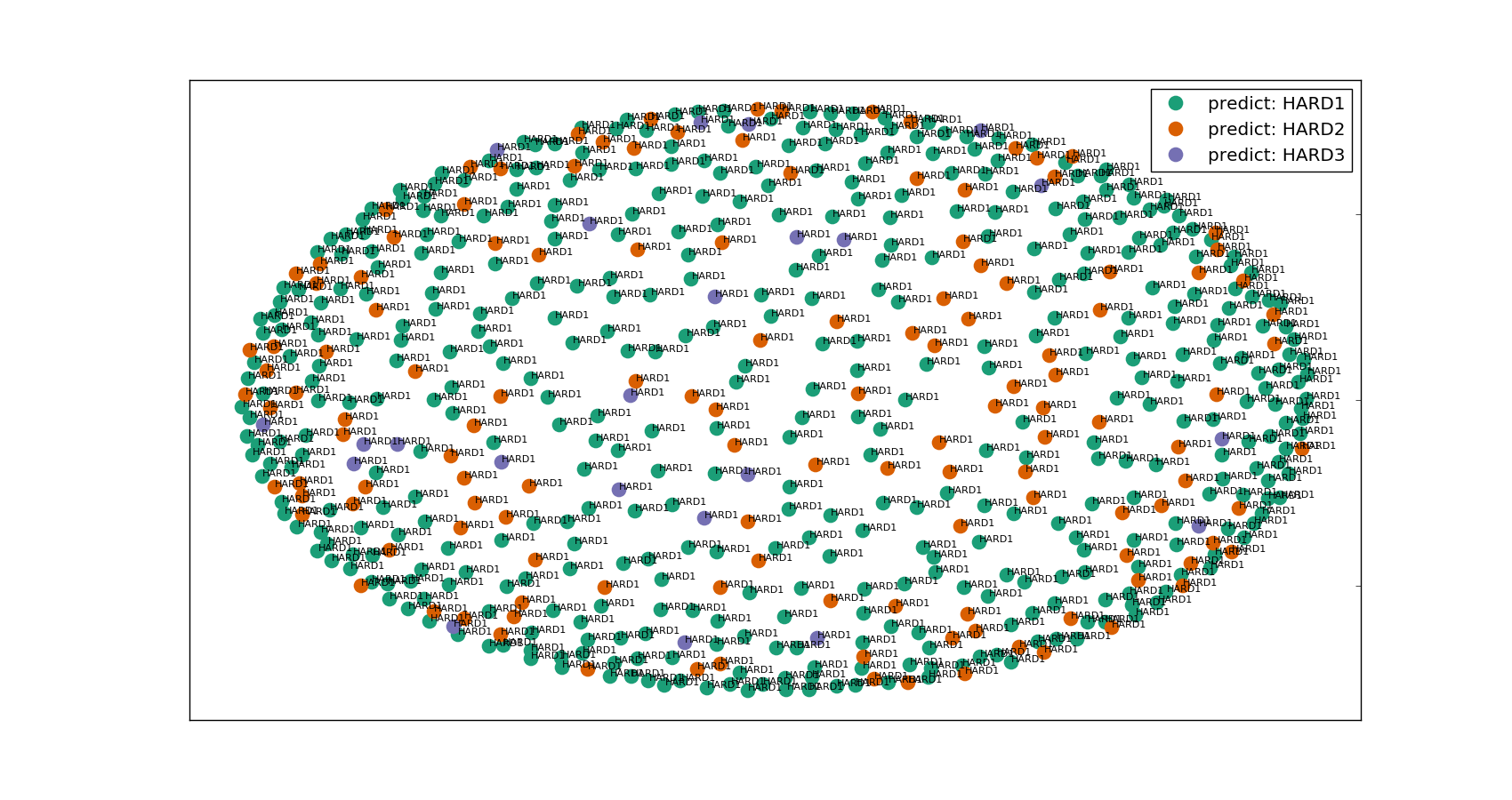
- Kmeans: As the simplest clustering method, Kmeans can takes in the raw dataset and attempts to make a pre-defined number of clusters. In here the number of clusters are set to be the number of different meanings of the word. Unfortunately, the model does not give very meaningful predictions. The figure below shows the result for Kmeans clutering for the dataset of the word "Hard" when projected to two-dimension. We can see right away that the "Curse of Dimensionality" prevents our clusters to separate well.
- Agglomerative Clustering: Since Kmeans can only use Euclidean distances as its affinity, the next logical thing to remedy this problem is to use Hierachical Clustering where cosine similarity or Jaccard similarity can be used. However, this algorithm is very memory-intensive, takes very long to run and does not yield good cross-validation accuracy, precision and recall results for the hyper-parameters I used. Due to the time constraint of this project, I decided to try another model.
- Linear Discriminant Analysis: Again, this model is just as memory-intensive as the Agglomerative model. The validation results are similar to that of the Agglomerative model.
2. Supervised Learning
Since all of the unsupervised methods did not yield good results, I decided to utilize the labels of the datasets to make supervised predictions.
- Multinomial Naive Bayes: This model is simple, yet has the potential to make good predictions. By adjusing the hyper-parameter alpha for the model, I found that alpha = 0.12 is optimum. The accuracy, precision and recall averages for a few different homographs are shown below.
| Word | Accuracy | Precision | Recall |
|---|---|---|---|
| "HARD" | 72% | 74% | 80% |
| "INTEREST" | 75% | 73% | 75% |
| "LINE" | 72% | 74% | 72% |
When compared the base algorithm where we always predict the most common meaning of a word (with accuracy between 51.4% and 57%), this model seems to perform better.
Conclusion
The Multinomial Naive Bayes model is simple, yet effective for the purpose of this project. Since the model can be applied as long as we have a labeled dataset, it can be extended to other languages, even non-latin languages such as Chinese or Japanese. For the time being, this model is quite bulky (we need one model for each word), but it can be improved in the future.